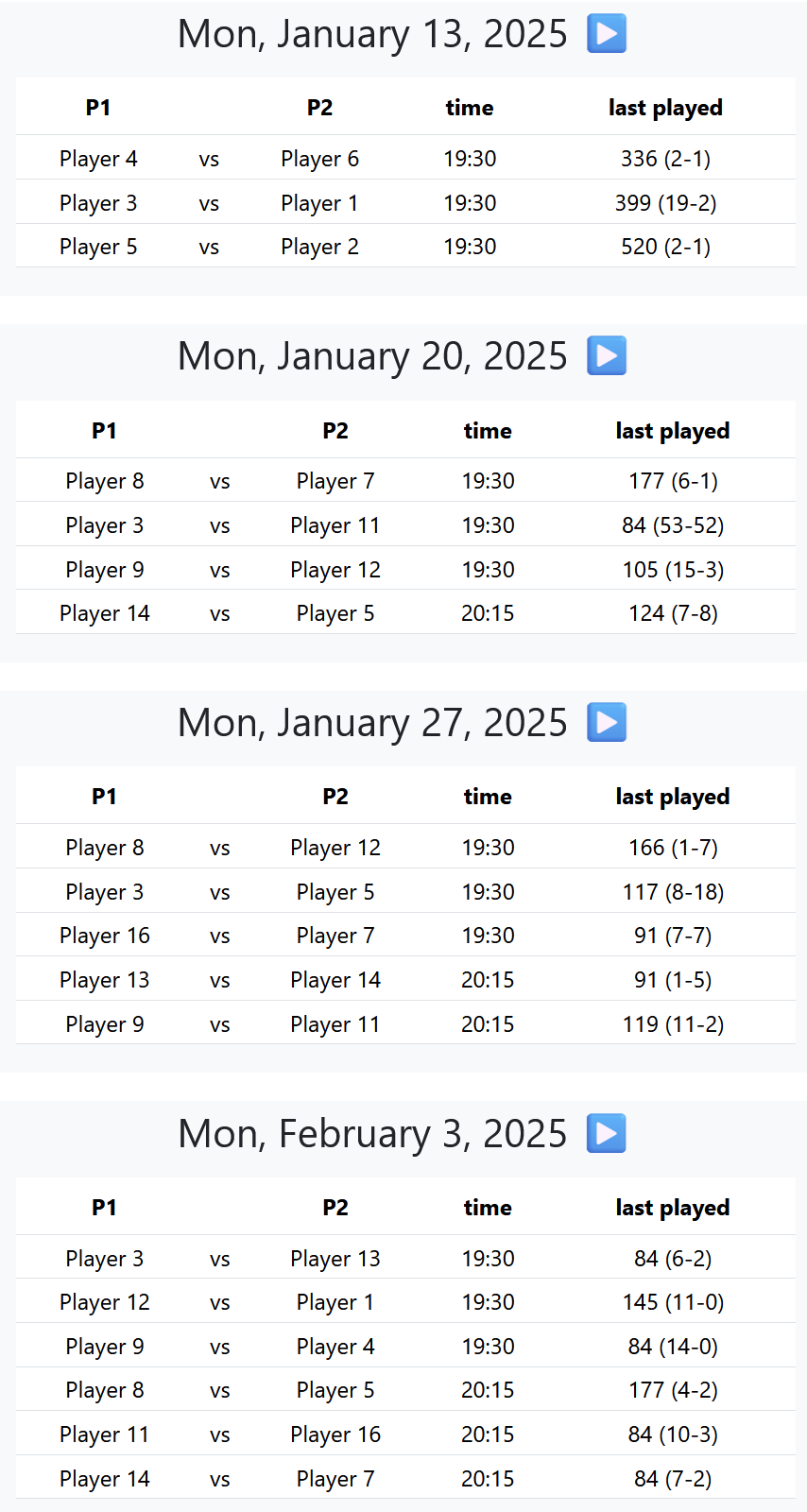
I have not avoided KiCad in any way, I just don’t use ECAD software much, and when I do, it’s largely for work where we have always used Altium. This year we got some work done by a contract firm. They mentioned they could use Altium, but it was their preference to use KiCad instead. We said that was fine. And all was good in the world.
Several months later and we want to produce something they’ve designed. They provide us all the KiCad files as well as manufacturing outputs, but for us to release this internally, we need to have it formatted in a specific way to match our QMS expected templates. This should be easy though, just apply a template and we’re good. KiCad has a Drawing Sheet Editor which lets you create worksheets, and apply them to your schematics and boards, that sounds like what we need.
And that is true. For schematics, I was able to create a template exactly matching our Altium one, and easily generate documents matching our existing documents. PCBAs on the other hand was a whole different ball game. This ‘issue’ is largely self-inflicted. Our release documentation requires a lot of things to be present in a 3-page PDF that aren’t necessarily that important. Mainly because it’s just duplicating data that is already contained in the Gerbers and other manufacturing output. This is just placed in a PDF that makes it easy for a human to get a quick overview of the design. It has its place.
Example output of a generated PDF sheet that includes a 3D image generated by the KiCad CLI (details)
Included in this document are: a 3d-isometric view of the board; a PCB stack-up table; drill map; and a single page with all the layers shown. And Altium’s templates makes this trivial to generate for new designs. KiCad does not. And that’s not KiCad’s fault, it shouldn’t set out to just replicate everything Altium does. These aren’t things that are needed in an ECAD software, it’s just, we had it, and now we don’t.
So what can we do? We can apply a worksheet template to the PCB editor. But it can only really output each layer on a separate page. It’s a start. We can also have custom layers, and put whatever we want on those custom layers, which can be output to separate pages. What can’t we do? Mainly, the Drawing Sheet Editor (as far as I could tell) doesn’t let you template these additional layers’ contents. It can’t generate 3d images of the board, it can’t automatically populate a drill map or board stack-up table. KiCad does support most of these things, just not in an automated template kind of way, so if I wanted to to do this for every new design we release, it’s a lot of time consuming, error-prone work, to get the desired output.
What KiCad does have though is a newly revamped API, as well as several CLI options. And what can we do with these? Well, we can get a long way to matching our Altium implementation.
We can take 3 new layers, and pretend each of them is the desired output page we want. We can use the CLI to do things like generate drill maps and 3D views of the board. We can apply template sheets to the project, and we can generate the final files. We can then use the API to add the elements to our 3 layers; get information from the board and automatically generate table outputs. And then we can piece this together with a PDF editor library. Do we get exactly the same output as with Altium? No, but we get pretty close, and it has everything we need.
You can see a semi-stripped down version of this on GitHub.
Moving to Ottawa I was lucky enough to fall into a great group of squash players at my local club. A bunch of the players had a standing appointment every week, and we’d rock up and play some squash. It was a bit haphazard as to who you would play, but you always got a match. One of the members eventually started pre-scheduling the matches for everyone, using one of various online round-robin calculators, this way it ensured you got a match, and, for the most part, meant you got to play someone different each week.
The online, free, round-robin generating software isn’t that great though. It lets you plug in a bunch of names, and it generates one full round robin, which was then applied to each week. But not everyone is available every week, so you end up manually making changes, and before you know it, chaos reigns, and you’re playing the same person multiple times.
To be fair, this isn’t a major reason to do what I did, but it was certainly a contributor. One of the great things about squash in Ottawa, is they use on an online ranking system called Rankenstein. It’s used by pretty much everyone in the greater Ottawa region, and it’s used both for scheduling and tracking the City League, as well as tournament records, and challenge matches. With this data available to me, a desire for a better scheduling system, and a node.js learning side-quest, I was set.
Most of the system was fairly straight-forward to develop. There’s nothing particularly fancy about what I did. I would schedule a month’s worth of matches at time, soliciting everyone’s availability, and only scheduling a match for those people who expect to be there. I also have access to the Rankenstein data, so I can see when last everyone played each other, whether part of our weekly forays, or in a separate context.
With this information I had everything I needed to schedule matches for everyone, every week, with the data in-hand to reduce the likelihood of a repeat match. I just had one piece out-standing, how do you actually figure out a round-robin schedule.
If you’re just creating a simple round-robin for X players, it’s pretty straightforward. If you have 6 players, you just pair player 1 up with each player week after week, then player 2, etc. If you have an odd number of players, you just add a “Bye” player. Then you get a simple round robin like this:
week 1
week 2
week 3
week 4
week 5
1v2
1v3
1v4
1v5
1v6
3v4
2v6
2v5
2v3
2v4
5v6
4v5
3v6
4v6
3v5
But this isn’t the only solution. Yes, you can switch the week’s around, but there’s also different combinations of ways you can have people playing. For example, if we just looked at the first week, if we say 1 is going to play 2, you can also have 3v5 (with 4v6) and 3v6 (with 4v5).
And it was with a pen and paper as I was trying to figure out these various combinations that I noticed an underlying pattern. If we have 2 players, there’s only 1 possible combination. If we have 3, we include a bye player, so we have 4 players. With 4 players, there is also only one set of options. 1v2 & 3v4, 1v3 & 2v4, 1v4 & 2v3. With 5 or 6 players, just pull out the two players and have them play each other, and the last 4 play the above solution. So we have 1v2, 1v3, 1v4, 1v5, 1v6, and for each of those, the other 4 play the above solution. If we then went to 2v3, and tried to generate the rest, we’d end up repeating one already created, so it’s not necessary.
So for a 4 player pool, we have 3 potential sessions. For a 6 player pool, we have 3 potential sessions for each 4 player pool, which is left over from the 5 player possible matches, for a total of 15 matches.
If we pushed that up to 8 players, we do the same thing, we pull out 1v2, 1v3, 1v4, 1v5, 1v6, 1v7 and 1v8, then recursively call the function for the remaining 6 players. Which gives us 7 possibilities, times the original 15, for a total of 105. so for an even number of players N greater than 4, the number of potential sessions is a geometric progression. 6 players = (6-1)*3. 8 players = (8-1)*(6-1)*3. 10 players = (10-1)*(8-1)*(6-1)*3.
This can get quite large; for 12 players it would be 10,395 sessions, each with 6 matches. Fortunately the computer is doing all the hard work, and we’re usually limited to a max of 14 players. I’m also only scheduling one week at a time, so I don’t have to figure out perfect rounds for n-1 weeks.
function get_all_possible_sessions(players)
{
if (players.length % 2 != 0 || players.length < 2)
{
logger.warn("get_all_sessions - number of players not even or less than 2");
return [new Session("",[],[new Match(-1, -1)])];
}
else if (players.length == 2)
{
return [new Session([new Match(players[0], players[1])])];
}
else if (players.length == 4)
{
let allSessions= [];
allSessions.push(new Session([new Match(players[0], players[1]), new Match(players[2], players[3])]));
allSessions.push(new Session([new Match(players[0], players[2]), new Match(players[1], players[3])]));
allSessions.push(new Session([new Match(players[0], players[3]), new Match(players[1], players[2])]));
return allSessions;
}
else
{
let allSessions= [];
for (let i = 1; i < players.length; i ++)
{
let match = new Match(players[0], players[i]);
// let tempPlayers = structuredClone(players); only introduced in v17
let tempPlayers = JSON.parse(JSON.stringify(players))
tempPlayers.splice(tempPlayers.indexOf(players[0]),1);
tempPlayers.splice(tempPlayers.indexOf(players[i]),1);
let sessions = get_all_possible_sessions(tempPlayers);
sessions.forEach(session => {
session.matches.push(match);
});
allSessions.push(...sessions);
}
return allSessions;
}
}
Before I looked at how to program this particular topic, I had spent some frustrating time with ChatGPT, trying to get it to give me something useful, but I really struggled to get it to understand what I wanted. No manner of, “that’s not what I asked for, I actually want…” seemed to be able to get me what I want. It’s possible that newer models will perform better, but in the end I’m happy I was able to figure out a straight-forward solution myself.
Once we have all the session and match combinations, we update each one specifying when last those two players played each (or are scheduled to play each other). We also pass in information related to scheduled byes, to try avoid the same player being scheduled a bye more than once in a set.
Put it all together and you can share a link to your group with something like this:
You’ve got the matches for each week, along with how many days since the players last played each other, and a historical win ratio.
There’s a login field for whoever’s administrating, and they get the same interface with additional options to make changes, schedule new sessions etc. They can manually override matches if someone can’t make it anymore. You can also manually schedule some games, and then let the system generate the remaining matches, based on players not yet scheduled.
It’s been almost a year since I started using this for the scheduling, and it’s worked pretty well. I’ve made small improvements and adjustments over the year, and it works pretty well for what it is. There’s definitely more complex stuff I’d like to do withe project, but the amount of time to implement it just doesn’t warrant the small benefit I’d experience from it, so for now this project is pretty much complete.
The project is written in Node.js, using Express and ejs templates. My biggest issue is that at the time, my web-host only let me run Node.js 14, although it looks like they now support up to 22. The next project is in the works, time to tick React off my development checklist.
There are many aspects of IOT/connected devices that appeal to me. I like looking at data, it’s interesting. I like automation, it can be fun, and convenient. Unfortunately there are many aspects of the current IOT landscape that are extremely unappealing. Universally, not just to me. The obvious solution then is to build my own :)
And that’s what I’ve started doing. Over the past five years, little by little, as I’ve wanted to do something, I’ve put something together, based on what I’ve got lying around. Originally I was making use of a web-based server to store and gather all my data, but got annoyed each time the internet cut off. In hindsight it’s not clear to me why I was experiencing so many connectivity issues at the time that I decided the best option was to host something locally, but that’s where we are today.
Server
The server is a Raspberry Pi. One that I had lying around, and I already had submitting temperature and air pressure data to my server. The server was just a shared hosting site with a few basic php commands to link up with a sql database. To provide some flexility, allow for some customization and make up for my large lack of web-dev experience, I chose to do it all in python. I’m using the CherryPy library to present a basic html web-interface that gives me a summary of what’s going on, and also handles all the data requests coming in from various local sources. If the internet goes down, it doesn’t matter, because everything is stored and presented on the local network.
Every time I look at this jumble of wires I tell myself that I should really tidy it up. But it’s working. And then I’d have to take it offline, and the risk of a short isn’t thaaat high. So what would I really get out of the exercise?
At times, like when I’m away from home and need to monitor some things, I can open another port and make it accessible from the internet, but this is off by default, mainly as a security improving effort.
What does it do?
As I worked on integrating the few sensors I had, I realised that this platform I was creating could do more than just save some data and show it to me. Well, more than just weather data. The platform running python made it easy to script all kinds of integrations. As I created more of these, I saw the value in having a standard task based framework on which to build all these integrations.
This basis of this is a config file which is read at startup, that reads what tasks need to be load and when they must run. After that, there’s nothing left to do. All the tasks run as scheduled, doing as they must. The main web-interface shows a status for each task, when it was last run, when its next scheduled run is as well as options to start and stop tasks or run them immediately.
Screenshot of the web-interface. Some very useful statuses in there
This scheduler approach is simple. It makes it easy to expand, and it all running on python means it’s easy for me to think of something I want done and implement it, as well as feed back all the results to the ‘server’ directly.
Connected items
So what all is included in my setup?
Raspberry Pi
The Raspberry Pi itself has a BMP180 and an MH-Z19 directly connected to it that it polls occasionally for the latest temperature, air pressure and CO2 levels in my office.
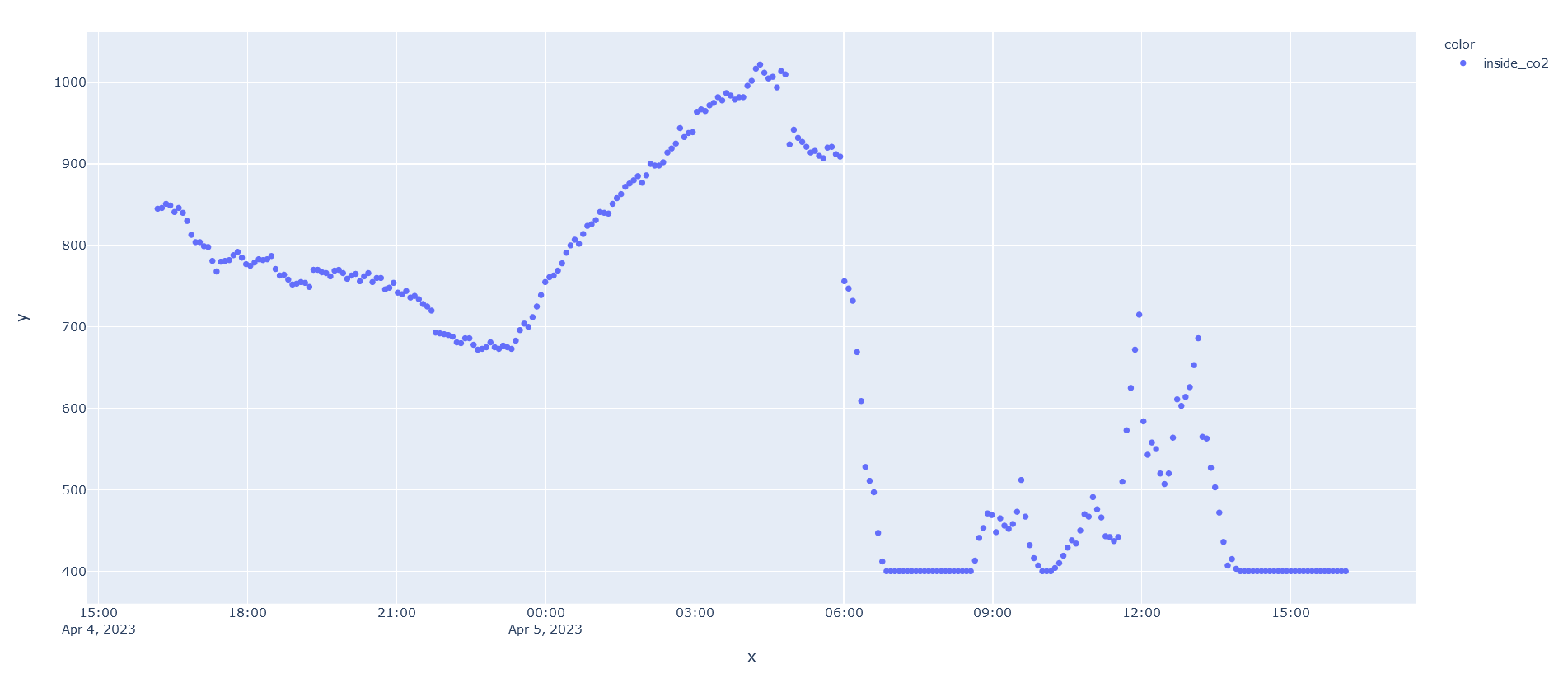
The CO2 sensor was pretty cheap, and accuracy isn’t amazing, along with its ‘auto-calibration’. But it still gives interesting results. It’s especially easy to see build-up in my office when the door is closed, as well as the drop every time the heating runs in the winter, bringing fresh air in. It’s certainly more accurate than this.
CO2 data. Big dip is when the furnace started up after ~12 hrs of not running on a cold (windows closed) but sunny day. Smaller spikes during day are from me closing my office door during a meetingAnd some temperature data to go with it. I think the green spike was some sun shining on the sensor
ESP32
I ‘attended’ one of the Hackaday Remoticon sessions a couple years ago, where someone from DigiKey was presenting on an IOT platform (Machinechat) that they were selling. It did a lot of what I wanted, but the free tier was pretty limited, and why would I pay for something when I can do it myself for free ;) But I had the microcontroller and temperature sensor leftover, so just repurposed it to connect to my own server and feed temperatures from our downstairs.
ESP32
A more recent addition to the collection, and not related to a specific task, but just some extra code I’ve implemented for logging and status. When we moved into our rental, we were given one of the large garage remote controls. But, especially in the summer, my wife and I mostly cycle, and these remotes are bulky and annoying. We bought one of the smaller remotes, but my wife and I are often out separately. So now we can open the garage via Wi-Fi.
The ESP runs a basic web-server, just waiting for a request to open the garage door. I need to still install a sensor and feed this data back to the server. And if I’m doing that, I might as well monitor the temperature in the garage too…
You see a yoghurt container, I see the perfect container for a microcontroller, a relay and some LEDs
Other Tasks
Beyond the local devices actively pushing data to the server, there are a number of tasks that get run for ad-hoc items.
Outside Temperature
Lacking an outside connected thermometer, I instead choose to just pull data from the weather api every 20min.
Data plotting
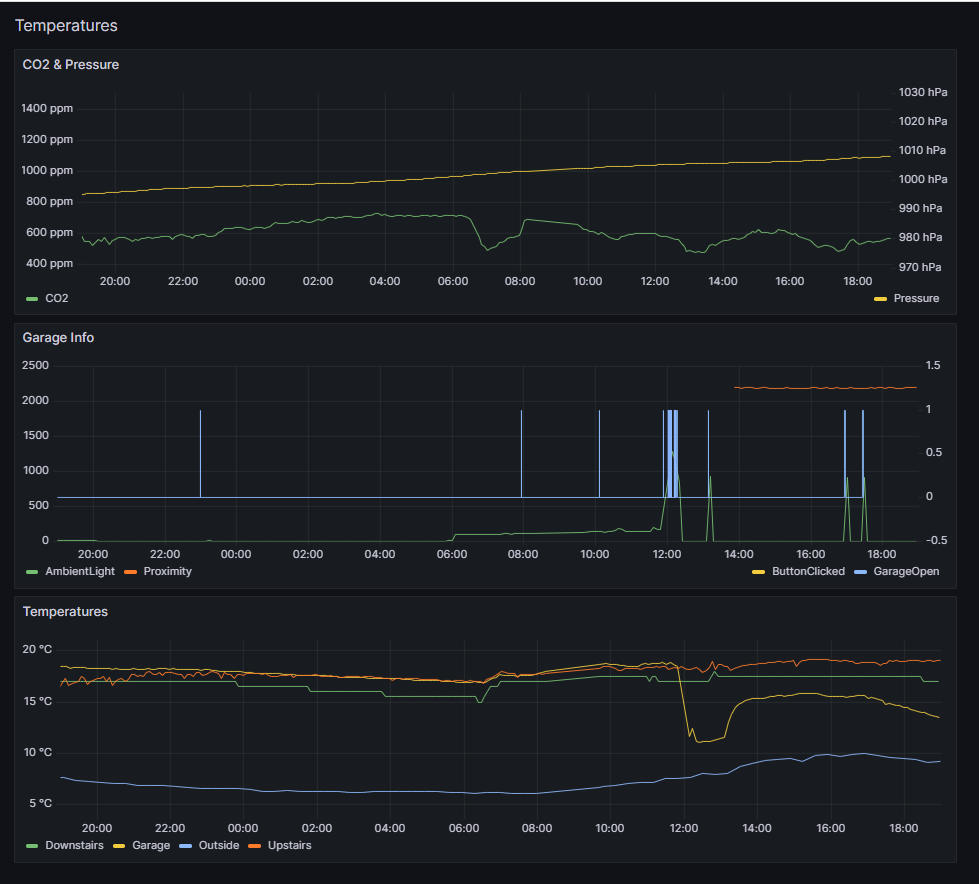
Instead of learning how to plot data on the fly in a web-friendly format. I chose the lazy route I already had experience with, which is using python’s Plotly library to generate an interactive html graph. And because doing this on the fly on a raspberry pi can be very slow, I just do it every few hours, and supply the last generated one when requested. This can be improved. (UPDATE: I installed grafana, see screenshot at the end of the post)
NAS Wake/Sleep
I have a NAS downstairs, it can be a bit noisy. I only ever need to use it at night, which is also when it needs to be on to perform internet backups. So I get this task to use WoL to start it up in the evening, and an ssh command to put it to sleep in the wee hours of the morning.
Get external IP
At some stage I started setting up cloudflare to redirect a domain to my homeserver. I never completed this, but I did write a script to monitor our external IP address and update me via e-mail whenever it changed.
Strava
Earlier this year, Strava added Squash to their list of supported activities. I’d done a lot of squash activities, that were listed as Workouts. So I went about setting the record straight, using the Strava API to update all my previous activities that matched the criteria to be Squash. With all that done, I extended it to start adding weather data to my outdoor activites and ensuring that all my future squash activities get listed as such (Garmin don’t support Squash, so my activity still gets sent to Strava as a Workout, and then the script updates it). So now I have a web-hosted server that Strava notifies whenever I (or other people) complete an activity. My raspberry pi polls this server occasionally and runs scripts locally to determine if anything needs to happen, and then update activities as necessary.
You have to give whatever’s accessing the Strava API a name, thus StraWeer was born
Express Entry
At one stage we had an application in for Canadian Express Entry. They released new results usually once a week, but not at fixed times, and occasionally more than once per week. So I set this task to scrape the site where they posted the results and e-mail whenever it got updated with the latest results. Sometime after it was no longer applicable to us, the website was updated to no longer provide the information with a standard http request. So I stopped running it.
I started on this project a long time ago, and would often not look at the code for months or years, then update it to do something I wanted. It certainly has a lot of shortcomings, a lot of opportunity for improvement, and would do well to better implement a lot of things I’d consider good programming practice these days, but were not top of my mind at the time. That being said, it works. The fact that I only have to do something to it when I want to make an improvement is evidence of this. My biggest ongoing concern is when the Raspberry Pi’s SD card is going to pack up :D
And then
Most of the code that runs on the Raspberry Pi is available in the below repo. I’m still updating it with some of the Strava integration stuff, but I need to do some more improvements first
(apparently I drafted this at the end of 2018, and am only publishing it now in 2023…)
Smart things in the context of IOT is a huge market. If you can put Wi-Fi in it, someone has tried, and someone has tried to market it. I like this. It’s fun. I enjoy being able to remotely control things from my phone or with my voice, as opposed to having 20 remote controls, one for each item. It is good. However it is not without issue.
One of the prominent issues surrounding IOT is security. If you can remotely access these things, especially sensitive things like video cameras or alarm systems (or large infrastructure), then there’s a chance that someone else (unintended) can too. This is concerning, although not my biggest issue.
I don’t disagree that security is important, but I think it’s manageable. My biggest gripe with these products is redundancy. Firstly the immediate, what if their servers have issues or what if my internet is down. But of greater concern to me, is what about when the company decides to no longer support my product. And this isn’t an if, it’s very much a when.
The vast majority of mainstream products require you to setup an account with them and then control your devices through theirs- or a compatible app. They work great (sometimes). Until they don’t. I’ve posted recently about how Nike have shutdown their servers for their GPS watches. The servers that you are required to connect to if you want to download data from your device. And there are many companies that have done similar things in recent years, and many more are still to come.
My issue is that there’s no reason for many of these services to require distant servers to control them. It’s one of the reasons I have limited our smart device purchases to a number of light bulbs that, at the end of the day, will at least still act like normal lightbulbs, even if the servers go out. But what are the alternatives?
I did also buy one of these, but I’m not going out into the snow everyday to turn on the Christmas lights
Mainstream manufacturers do this for a number of reasons. I like to think mainly it’s because it truly is the easiest way for them to provide the best customer service. It is the easiest way to ensure customers get a product which works, and will continue to work as long as the manufacturer wants it to work. But obviously this also means there is some level of forced obsolescence too, never mind the data gathering opportunities.
I get that companies can’t carry on supporting old equipment forever. Keeping servers running as fewer and fewer users need them. Not getting any additional revenue for the cost. But the least they can do is release software at the end of a product’s life which allows a product to still be useful. Nike could easily have released a stand-alone product that could download the GPS data to my computer, and I’d still have been happy. Makers of other products could release firmware to allow local/direct control of electronics that otherwise require servers, and will just end up in the landfill. But they don’t.
So what is the solution? Doing it oneself? There are many downsides to this. Whatever I put together will not work as well. I don’t have the knowledge of hundreds of product developers. It will probably have more downtime than any product you purchase, because I’m not going to pay for the most reliable servers and products. But at least I’ll be able to keep it running as long as it’s useful to me. And that’s what I’m doing.